Abstract
Benchmark Everything, Everywhere, All at Once
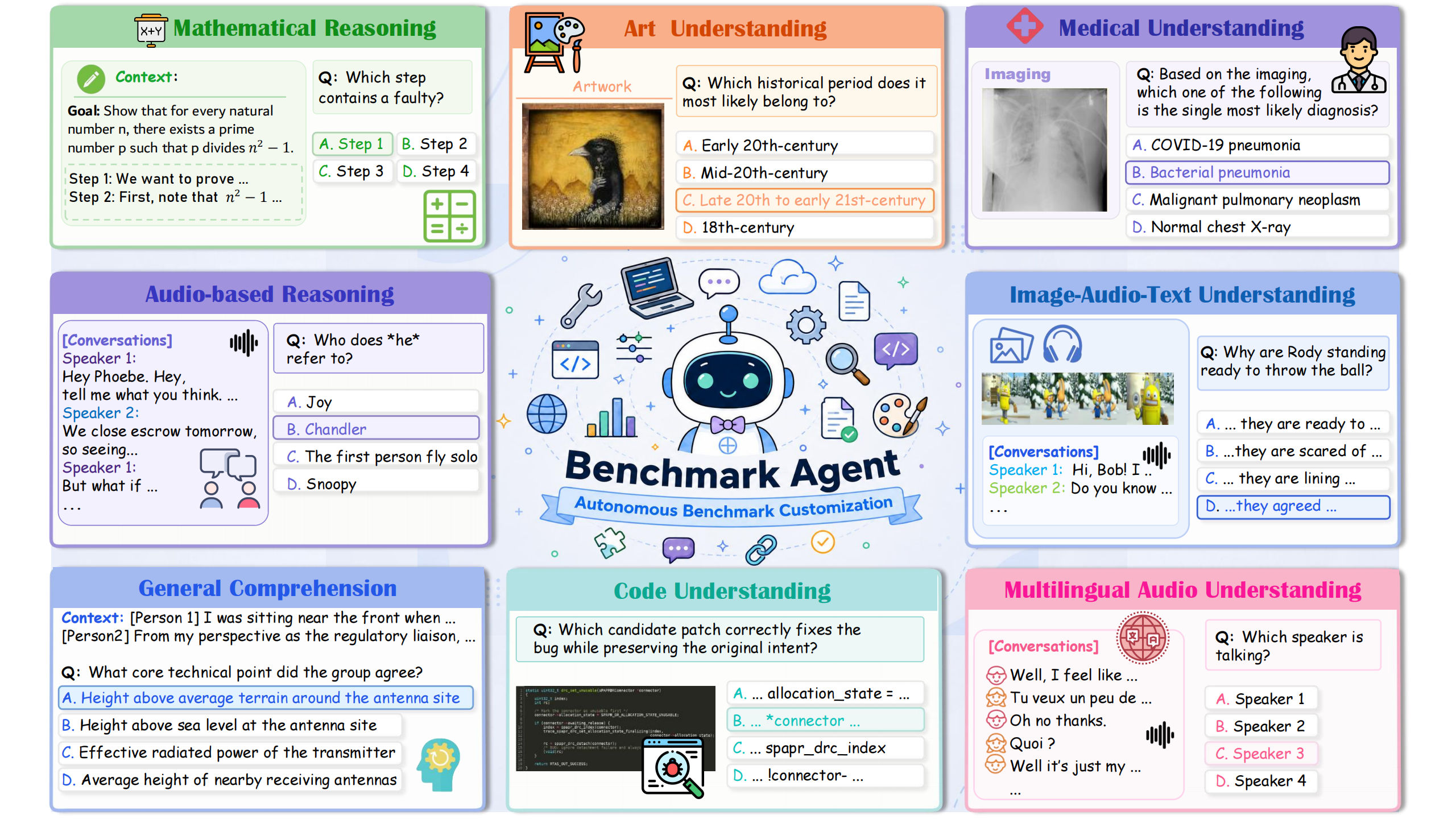
Benchmarks are crucial for evaluating LLMs and MLLMs, yet their construction is labor-intensive, difficult to scale, and often prone to rapid performance saturation.
We present BenchmarkAgent, a fully autonomous agentic system that standardizes and automates benchmark construction, covering user requirement analysis, subtask design, data annotation, and quality control.
Across 15 representative benchmarks spanning text, multimodal, and domain-specific reasoning, BenchmarkAgent produces high-quality samples with minimal human involvement, as validated by human evaluation, LLM-as-a-judge assessment, and consistency checks.
We present BenchmarkAgent, a fully autonomous agentic system that standardizes and automates benchmark construction, covering user requirement analysis, subtask design, data annotation, and quality control.
Across 15 representative benchmarks spanning text, multimodal, and domain-specific reasoning, BenchmarkAgent produces high-quality samples with minimal human involvement, as validated by human evaluation, LLM-as-a-judge assessment, and consistency checks.